我們擅長商業策略與用戶體驗的完美結合。
歡迎瀏覽我們的案例。
現在提到 AI 的時候,大家已經很少聯想到電影《終結者》中的天網那樣有自己獨特思維邏輯以至于得出了反人類結論的「超人類智能」了。這當然是件好事,說明我們都知道了現階段的 AI 并不具有那樣的邏輯思維能力,沿著現有方向繼續發展下去也不會有;也說明我們已經了解了身邊就有形形色色的運用機器學習解決具體問題的技術成果。
但我們同時也面對著一個新問題,就是隨著人類用模型做出越來越多的決策,模型所看重的因素真的和設計它的人類所希望的一樣嗎?又或者,模型完全捕捉了設計者提供的數據中的模式,但數據本身卻含有設計者沒有意識到的偏見。這時候我們又要怎么辦?
DeepMind 安全團隊的這篇文章就對相關問題做出了一些討論、提出了一些見解。它概述了 DeepMind 近期一篇論文《Scalable agent alignment via reward modeling: a research direction》中提出的研究方向;這篇論文試圖為「智能體對齊」問題提供一個研究方向。由此他們提出了一個基于獎勵建模的遞歸式應用的方法,讓機器在充分理解用戶意圖的前提下,再去解決真實世界中的復雜問題。雷鋒網 AI 科技評論編譯如下。

近些年,強化學習在許多復雜的游戲環境中展現出令人驚嘆的實力,從 Atari 游戲、圍棋、象棋到 Dota 2 和星際爭霸 II,AI 智能體在許多復雜領域的表現正在迅速超越人類。對研究人員來說,游戲是嘗試與檢驗機器學習算法的理想平臺,在游戲中,必須動用綜合認知能力才能完成任務,跟解決現實世界問題所需的能力并無兩樣。此外,機器學習研究人員還可以在云上并行運行上千個模擬實驗,為學習系統提供源源不斷的訓練數據。
最關鍵的一點是,游戲往往都有明確的目標任務,以及反映目標完成進度的打分系統。這個打分系統不但能夠為強化學習智能體提供有效的獎勵信號,還能使我們迅速獲得反饋,從而判斷哪個算法和框架的表現最好。
讓智能體與人類一致
不過,AI 的終極目標是幫助人類應對現實生活中日益復雜的挑戰,然而現實生活中沒有設置好的獎勵機制,這對于人類評價 AI 的工作表現來說形成了挑戰。因此,需要盡快找到一個理想的反饋機制,讓 AI 能夠充分理解人類的意圖并幫助人類達成目標。換句話說,我們希望用人類的反饋對 AI 系統進行訓練,使其行為能夠與我們的意圖保持一致。為了達到這個目的,DeepMind 的研究人員們定義了一個「智能體對齊」問題如下:
如何創建行為與用戶意圖保持一致的智能體?
這個對齊問題可以歸納在強化學習的框架中,差異在于智能體是通過交互協議與用戶進行交流、了解他們的意圖,而非使用傳統的數值化的獎勵信號。至于交互協議的形式可以有很多種,當中包括演示(模仿學習,如谷歌的模仿學習機器人)、偏好傾向(人類直接評價結果,如 OpenAI 和 DeepMind 的你做我評 )、最優動作、傳達獎勵函數等。總的來說,智能體對齊問題的解決方案之一,就是創建一個能讓機器根據用戶意圖運作的策略。
DeepMind 的論文《Scalable agent alignment via reward modeling: a research direction》中概述了一個正面解決「智能體對齊」問題的研究方向。基于過去在 AI 安全問題分類和 AI 安全問題闡述方面所做的工作,DeepMind 將描述這些領域至今所取得的進展,從而啟發大家得到一個對于智能體對齊問題的解決方案,形成一個善于高效溝通,會從用戶反饋中學習,并且能準確預測用戶偏好的系統。無論是應對當下相對簡單的任務,還是未來日趨復雜、抽象化的、甚至超越人類理解能力的任務,他們希望系統都能勝任有余。
通過獎勵建模進行對齊
DeepMind 這項研究方向的核心在于獎勵建模。他們首先會訓練一個包含用戶反饋的獎勵模型,通過這種方式捕捉用戶的真實意圖。與此同時,通過強化學習訓練一個策略,使獎勵模型的獎勵效果最大化。換句話說,他們把學習做什么(獎勵模型)與學習怎么做(策略)區分了開來。
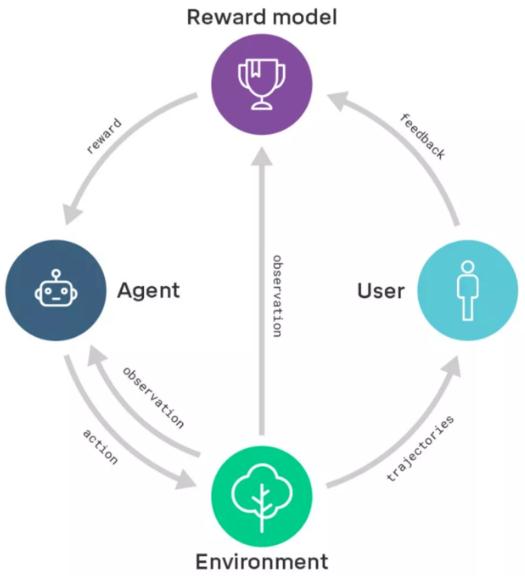
獎勵建模示意圖:獎勵模型基于用戶反饋進行訓練,以便更好地捕捉用戶意圖;同一時間,獎勵模型為經過強化學習訓練的智能體提供獎勵。
過去 DeepMind 做過一些類似的工作,比如教智能體根據用戶喜好做后空翻,根據目標示例將物件排成特定形狀,根據用戶的喜好和專業的演示玩 Atari 游戲(你做我評 )。在未來,DeepMind 的研究人員們還希望可以研究出一套算法,讓系統可以根據用戶的反饋迅速調整自己去適應用戶的行為模式。(比如通過自然語言)
擴大獎勵模型規模
從長遠來看,DeepMind 的研究人員們希望可以將獎勵模型的規模擴大至一些目前對人類評估能力來說還比較復雜的領域。要做到這一點,他們必須提升用戶評估結果的能力。因此,他們也將闡述如何遞歸地應用獎勵模型:通過獎勵模型訓練智能體,使其能在用戶的評估過程中提供幫助。一旦評估變得比行為簡單,也就意味著系統可以從簡單的任務過渡至更加普遍、復雜的任務。這也可以看作迭代擴增(iterated amplification)的實例(詳情見「超級 AI」的種子?復雜到人類難以評價的問題,可以教會一個 AI )。
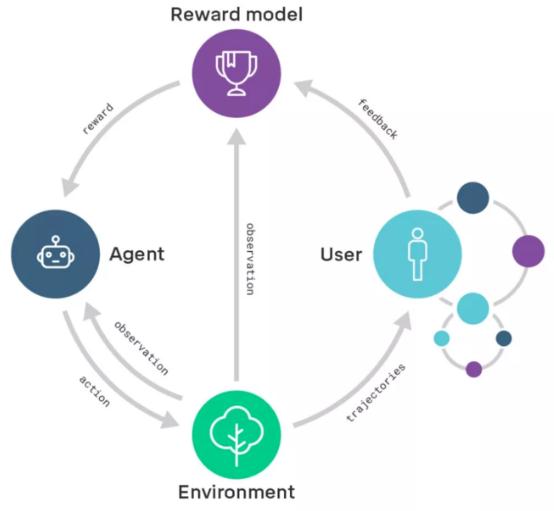
遞歸獎勵模型的示意圖:經過遞歸獎勵模型訓練的智能體(右邊的小圈圈)將幫助用戶評估由正在被訓練的智能體(右邊打圈圈)產出的結果
舉例說明,比如想要通過訓練智能體來設計計算機芯片,為了評估所提議的芯片設計的可行性,我們會通過獎勵模型訓練一組智能體「助手」,幫助我們完成芯片模擬性能基準測試、計算散熱性能、預估芯片的壽命、發現安全漏洞等任務。智能體「助手」輸出的成果幫助用戶評估了芯片設計的可行性,接著用戶可以據此來訓練芯片設計智能體。雖然說智能體「助手」需要解決的一系列任務,對于今天的學習系統來說難度還是有點高,然而總比直接讓它設計一個計算機芯片要容易:想設計出計算機芯片,你必須理解設計過程中的每一項評估任務,反之卻不然。從這個角度來說,遞歸獎勵模型可以讓我們對智能體提供「支持」,使其能在和用戶意圖保持一致的情況下,去解決越來越難的任務。
研究面臨的挑戰
如果想將獎勵模型應用到復雜的問題上,有幾項挑戰依然等待著我們去克服。下圖展示了 5 項在研究中可能面臨的挑戰,對此感興趣的同學可以查閱 DeepMind 論文,文中詳細描述了這些挑戰及對應的解決方案。
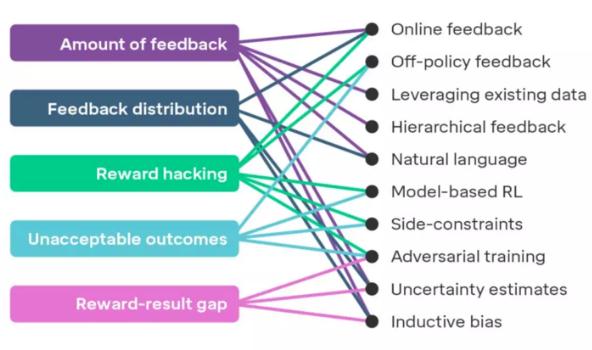
當我們擴大獎勵建模時將會遇到的挑戰(左側)以及最有希望的解決方案(右側)
這提醒了我們關于智能體對齊問題的最后一個關鍵要素:一旦要在現實世界中投入使用智能體,首先我們需要向用戶證明這些智能體已經充分對齊。為此,DeepMind 在文中提出了 5 項有助于提高用戶對于智能體信任度的研究途徑,它們是:設計選擇、測試、可解釋性、形式驗證和理論保證。他們還有一個充滿野心的想法,那就是為產品制作安全證書,證書主要用于證明開發技術的可靠性,以及增強用戶使用訓練智能體進行工作的信心。
未來的研究方向
雖然 DeepMind 的研究人員們深信遞歸獎勵模型會是智能體對齊訓練非常有前景的一個研究方向,然而他們目前無法預估這個方向在未來會怎么發展(需要大家進行更多的研究!)。不過值得慶祝的是,專注智能體對齊問題的其它幾種研究方向也同時有別的研究人員正在做出成果:
模仿學習
短視強化學習(Myopic reinforcement learning)
逆強化學習(Inverse reinforcement learning)
合作逆強化學習
迭代擴增(復雜到人類難以評價的問題,可以教會一個 AI )
通過爭論學習(人和人吵架生氣,但 AI 和 AI 吵架反倒可以帶來安全 )
智能體基礎組件設計(Agent foundations)
DeepMind 也在文中探討了這幾種研究方向的異同之處。
如同計算機視覺系統對于對抗性輸入的魯棒性研究對當今的機器學習實際應用至關重要,智能體對齊研究同樣有望成為機器學習系統在復雜現實世界進行部署的關鍵鑰匙。總之,人類有理由保持樂觀:雖然學術研究上很可能會在試圖擴大獎勵模型時面臨挑戰,然而這些挑戰都是一些有望解決的具體技術性問題。從這個意義上說,這個研究方向已經準備就緒,可以對深度強化學習智能體進行實證研究。
協助課題研究取得進展是 DeepMind 日常工作中很重要的一個主題。如果作為研究者、工程師或者有天賦的通才,有興趣參與 DeepMind 的研究中來,DeepMind 也歡迎他們申請加入自己的研究團隊。
(邯鄲網站建設)